CodeQuest: Lightweight Semantic Code Search for Efficient Retrieval
Introduction
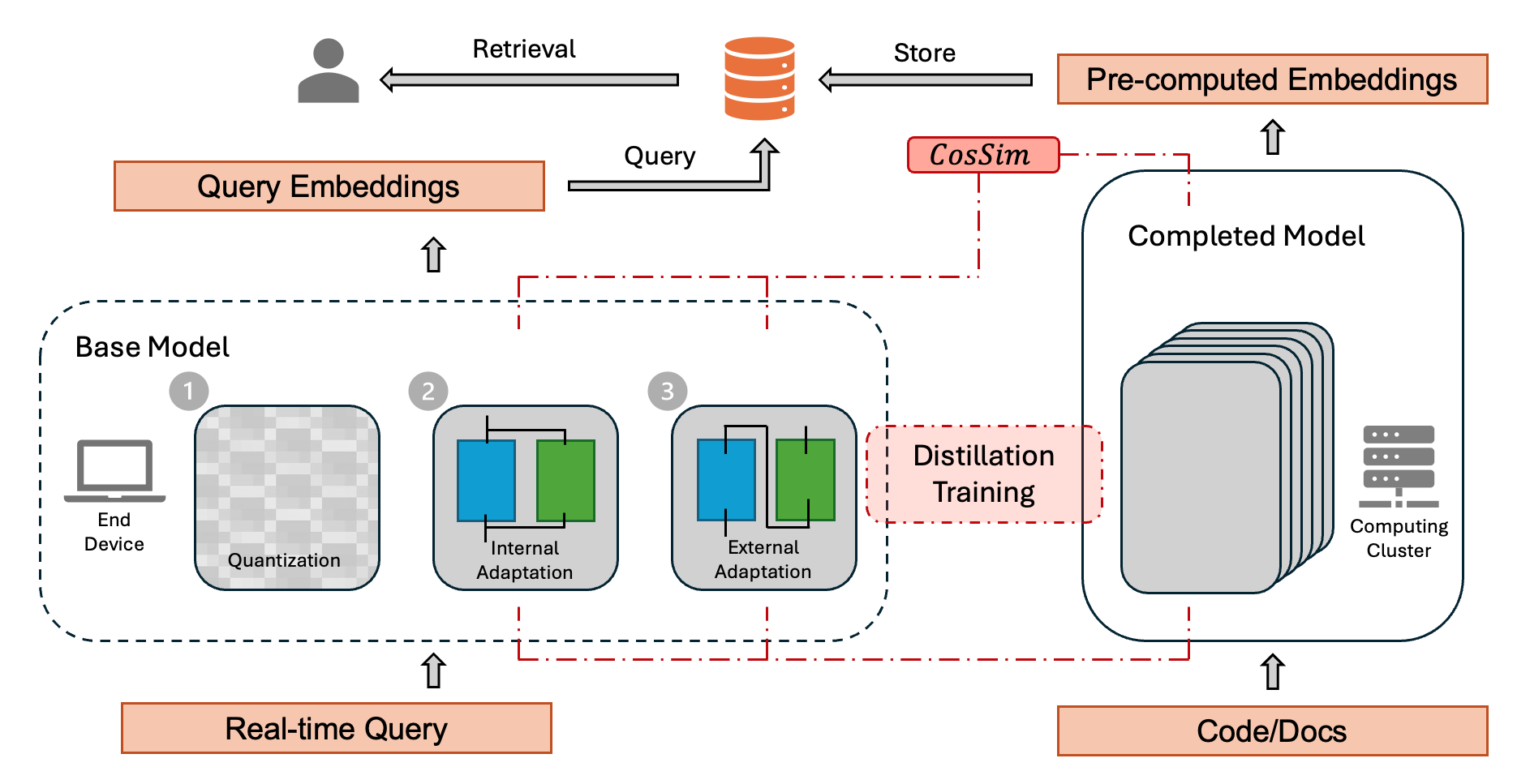
In this work, we accelerate code retrieval by replacing a large embedding model with a more efficient, lightweight alternative for query encoding. Specifically, we explore distilling a large model trained for both code and query processing into a compact model optimized solely for embedding queries into the shared representation space with code.
You can access our final report here. Our work is planned to further extend to the Puma, a local lightweight RAG-based code search engine for codebases.
Our experiments demonstrate that this trade-off between model size and accuracy is feasible, introducing a smaller neural network that balances computational efficiency with retrieval effectiveness.
Three Adaptations of Lightweight Embedding Model
Our objective is to enhance the efficiency of code retrieval in RAG systems by replacing a large query encoder (the complete model) with a more lightweight alternative while maintaining retrieval effectiveness. Rather than embedding both natural-language queries and code snippets using the complete model, we distill the knowledge from the complete model into a smaller lightweight model (base model) with adaptation. This enables a reduction in computational cost without significantly compromising retrieval performance.
The main challenge of the lightweight-query dual-encoder system is that two models embed into the same embedding space, as embedding spaces of different encoders are intrinsically different. We explore three key adaptation strategies that have the potential to achieve our goal: compact adaptation, which quantizes the full model with lower precision to reduce inference computation and memory usage; external adaptation, which post-transforms the base model’s embeddings into the embedding space of the full model; internal adaptation, which modifies the base model directly through fine-tuning.
Experiments & Analysis
We evaluate the effectiveness of the three adaptation strategies with extensive experiments. The following two figures show the t-SNE visualization of embeddings from adaptations and the approximated retrieval recall with respect to model complexity. It can be approximated that quantization, LoRA adaptation, and post-embedding refinement follow a log-linear relationship between computational cost and accuracy.